Free square tile grid map of the USA for PowerPoint and Google Slides. Abstract and minimalist map of the United States designed with a set of equal squares. Perfect to show comparative data of each state.
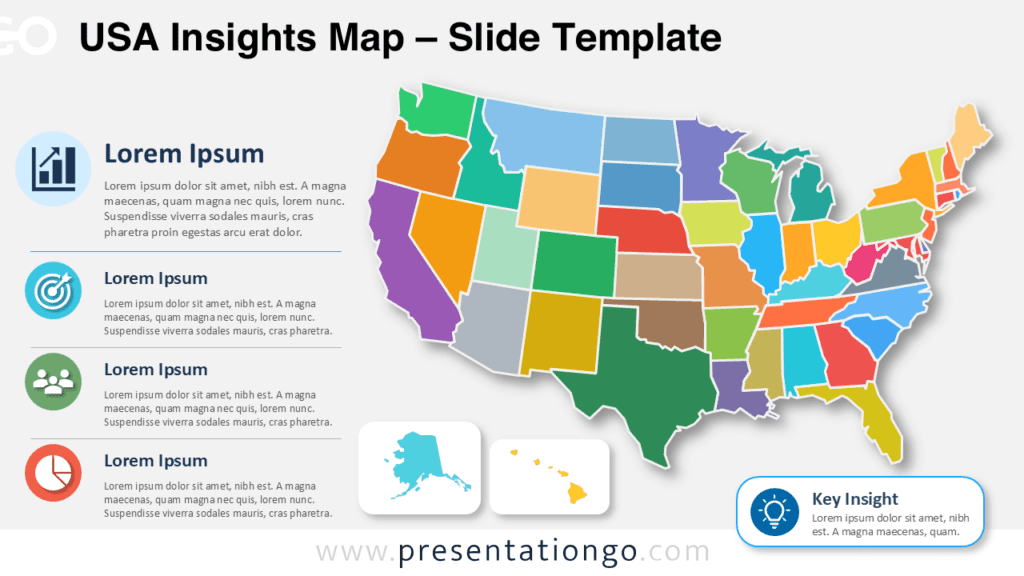
Square Tile Grid Map of the USA
Illustrating data information for each state of the USA could be a tricky exercise. Indeed, the relatively small size of some states makes this information harder to visualize.
Therefore, a new infographic design to map data has recently gained popularity: tile grid maps.
Tile grid maps minimalize the representation of geographic locations. More specifically, the reduction and uniformization of sizes and shapes create that simplification. Hence, each map area (here, the states) is abstracted into equal squares. And the map is created with an approximate arrangement in order to (roughly) re-create the original map. Finally, each state square embeds the corresponding two-letter abbreviation name.
While not being very accurate on a geographic scale, the interest of these maps is rather on the data visualization perspective. The main advantage of tile grid maps is that readers can easily and quickly read the data related to each region. And that is exactly the purpose of data visualization graphics.
You can use this Square Tile Grid Map of the USA to display data for every single American state. Each square shape will have a specific color that depends on a numeric variable.
This map will also be great for other purposes, e.g., to position offices, stores, warehouses, etc.
Shapes are 100% editable: colors and sizes can be easily changed.
Includes 2 slide option designs: Standard (4:3) and Widescreen (16:9).
Widescreen (16:9) size preview:


This ‘Square Tile Grid Map of the USA for PowerPoint and Google Slides’ features:
- 2 unique slides
- Light and Dark layout
- Ready to use template
- Completely editable shapes
- Standard (4:3) and Widescreen (16:9) aspect ratios
- PPTX file and for Google Slides
Free fonts used:
- Helvetica (System Font)
- Calibri (System Font)